The Corpus and the Courts
The legal corpus linguistics movement is one of the most exciting recent developments in legal theory. Justice Thomas R. Lee and Stephen C. Mouritsen are its pioneers, and their new article thoughtfully responds to critics. Here, Part I applauds their response as a cautious account of how those methods might provide relevant evidence about ordinary meaning in legal interpretation. Some disagreements persist, but The Corpus and the Critics makes significant progress in academic debates about legal interpretation. Part II turns from theory to practice: Judges are increasingly conducting sua sponte corpus linguistic analyses in their opinions, and this Essay collects and analyzes these cases. Corpus linguistics is theorized as apolitical, neutral, and objective. But in practice, it has been used largely by Republican-appointed judges, sometimes inconsistently with standards that Lee and Mouritsen recently endorsed. This Essay outlines a set of best practices, endorsed both by Lee and Mouritsen’s new cautious account and by many critics of the movement. If courts continue to employ legal corpus linguistics methods, the practice should be guided by at least these shared standards.
Introduction
Ten years ago, Stephen C. Mouritsen published a student note outlining the possibility of a new legal interpretation tool: corpus linguistics. A year later, Justice Thomas Lee employed legal corpus linguistics in a concurring opinion. The pair published a manifesto, and recently, dozens of other judges have used corpus linguistics analyses in opinions.
It is worth commenting on the movement’s remarkable development. Lawrence Solum predicted that legal “corpus linguistics will revolutionize statutory and constitutional interpretation.” Given the rise of textualist and originalist theories that center legal interpretation on empirical questions about “ordinary” and “public” meaning, it’s a good bet. If “empirical textualism” continues to shape legal interpretation, legal corpus linguistics is a promising tool.
The movement has also generated some criticism—well, more than just some criticism. In their recent The Corpus and the Critics, Lee and Mouritsen thoughtfully and insightfully respond to critics. Part I of this Essay applauds this recent article. It also notes several areas of convergence among Lee and Mouritsen and some of their critics but also remaining disagreements. Importantly, Lee and Mouritsen’s account endorses some best practices of legal corpus linguistics. These recommendations should serve as minimum standards for courts employing legal corpus linguistics.
Part II of this Essay turns from theory to practice. Alongside academic debate about legal corpus linguistics, judges increasingly cite and conduct legal corpus linguistic analyses in their opinions. Part II catalogues those cases and notes some trends. This survey should leave all of the academic discussants—corpus champions and critics—with shared concerns. Legal corpus linguistics is theorized as an apolitical and scientific interpretive tool, but it is largely being taken up by Republican-appointed judges, in ways that sometimes violate the best practices endorsed by both corpus proponents and critics.
I. The Corpus
This Part begins by outlining (I.A) legal corpus linguistics and (I.B) three positions in the current debate: corpus linguistics “enthusiasts,” “moderates,” and “skeptics.” Next Part I.C notes that the recent The Corpus and the Critics reflects Lee and Mouritsen’s endorsement of a moderate position.
An important feature of this moderate account is that good legal corpus linguistics is offered (merely) as relevant evidence of ordinary meaning (as Part I.D discusses). Lee and Mouritsen and their less skeptical critics agree: Good legal corpus linguistics can sometimes provide evidence of ordinary meaning, but it does not always constitute decisive or compelling evidence of ordinary meaning nor does it necessarily outweigh other sources of evidence.
So, one key question is: What makes for “good” legal corpus linguistics? This Part concludes (I.E) by cataloguing some best practices that seem to be shared by Lee and Mouritsen and other scholars in legal and nonlegal corpus linguistics. These best practices are considered again in Part II, which analyzes how courts have used legal corpus linguistics thus far.
A. What Is Legal Corpus Linguistics?
Corpus linguistics is the study of language in corpora. An enormous number of linguistic research projects employ corpus linguistic methods: from analysis of language acquisition, to prediction of what syntactic choices speakers will make, to study of words’ positive or negative prosodies. “Legal corpus linguistics” (LCL) has been used to describe one small subset of very recent work in corpus linguistics and legal interpretation, concerning the ordinary, public, or plain meanings of legal texts. The legal community’s critiques aimed at LCL are not critiques of the broader field of “corpus linguistics.” At the same time, much has been written about corpus linguistics, and some of those discussions inform LCL debates.
There is one small wrinkle in this terminology. Other legal scholars have recently used corpus linguistics methods to address different questions, such as whether congressional discourse has grown polarized over time or whether there is a relationship between gender-stereotyped language and judicial outcomes. These are undoubtedly “legal” projects and “corpus linguistics” ones, but the criticisms of “LCL” do not obviously apply to the use of corpus linguistics in answering these very different legal questions.
Lee and Mouritsen’s article and this Essay focus just on corpus linguistics as a tool to find “ordinary meaning” in legal interpretation. That project is especially relevant to originalist and textualist theories of constitutional and statutory interpretation. Those theories have conceptualized ordinary meaning as “an empirical question,” one about what a legal text would (in fact) communicate to an ordinary person. According to its proponents, this kind of interpretation is objective and predictable; moreover, locating ordinary meaning in ordinary people is democratic and promotes rule-of-law values like publicity.
As Lee and Mouritsen note, there are many approaches to uncovering a legal text’s ordinary meaning: Judges can use “intuition,” dictionary definitions, etymology, or linguistic canons. Judges might also look to survey studies of ordinary people as evidence of how ordinary people understand legal texts. Lee and Mouritsen’s earlier work presented corpus linguistics as a new (and often, “better”) tool to uncover ordinary meaning: “corpus analysis is superior to an intuitive guess (or, worse, crediting a dictionary or a word’s etymology).” Lee and Mouristen still remain skeptical about dictionaries, which “typically do not answer the ordinary meaning questions presented to courts.” But they now more clearly endorse a pluralistic account, which no longer characterizes corpus analysis as the (single) best tool (see Part I.C below).
As in their prior work, Lee and Mouritsen’s recent article focuses heavily on two corpus-linguistic tools: collocation and concordance line analysis. Collocation analysis is to evaluate which words occur most often in proximity with the term assessed. Concordance line analysis is to evaluate sentences from the corpus that use the relevant term. What exactly Lee and Mouritsen believe legal interpreters should conclude from these analyses is not entirely clear (more on that below). But these two modes of analysis form the core of their legal corpus linguistics proposal.
B. What Is the Debate About?
Consider three broad sets of reactions to Lee and Mouritsen’s proposal. One is that of the “corpus enthusiast.” On this view, legal corpus linguistics does not only tell us something about ordinary meaning, it is the best tool and one that is sufficient in determining ordinary meaning. Moreover, if legal corpus linguistics results conflict with the conclusion recommended by other interpretive sources (e.g., judicial intuition, a dictionary, survey evidence, etc.), under the corpus enthusiast’s view, judges should generally favor the conclusion recommended by legal corpus linguistics.
The opposite reaction is that of the “corpus skeptic.” On this view, legal corpus linguistics does not provide any evidence of ordinary meaning. As Donald Drakeman recently put it, to run these corpus linguistic analyses is no better than “flipping a coin.” Another critic in this camp is Stanley Fish, who has argued that legal corpus linguistics can reveal “patterns” of language use, but the resulting collection of data, stripped from its original contexts, tells us nothing about meaning: “Once you detach patterns from the intentional context in which they have significance, you can’t get the significance back.”
Between the corpus enthusiasts and corpus skeptics sit a wide range of intermediate positions: the “corpus moderates.” For the corpus moderate, at least some version of good corpus linguistics can provide at least some evidence of ordinary meaning, in at least some circumstances. I suspect that many of Lee and Mouritsen’s “critics” actually fall in this camp. For example, Stefan Th. Gries and Brian G. Slocum write optimistically about expert linguists (not judges) conducting legal corpus linguistics but also note that they “do not claim that corpus analysis should by itself set the meaning of a statute.”
C. What Is Lee and Mouritsen’s View?
Are Lee and Mouritsen corpus enthusiasts or moderates? Their position is hard to categorize. Much of their earlier work suggested a “corpus enthusiast” position. In Judging Ordinary Meaning (2018), they wrote that we should regard historical dictionaries “with skepticism when they are offered as evidence of ‘ordinary’ or ‘original’ meaning.” And in State v. Rasabout (Utah 2015), Justice Lee conducted a corpus linguistics search, advocating for its preferability to judicial intuition or dictionary use:
We could continue to judge the ordinary meaning of words based on intuition, aided by the dictionary. But those tools are problematic, for reasons explained above. And the impact of a judge’s mere gut intuition is entirely opaque. So it is our current methodology and tools that involve bad linguistics produced by unscientific methods. If the concern is reliability, the proper response is to embrace—and not abandon—corpus-based analysis.
Judging Ordinary Meaning cites this passage and reiterates dictionary-skepticism: dictionaries are “an unreliable source.”
There are some hints of a moderate view in their earlier work, but the recent The Corpus and the Critics (2021) clearly adopts the language of a “corpus moderate.” The traditional interpretive tools are not all deeply flawed and inherently problematic; instead, they are characterized as imperfect. Consider Lee and Mouritsen on dictionaries, intuition, and canons: “As with dictionaries or the use of judicial intuition, the point is not that linguistic canons are never helpful. It’s just that they may not always be independently up to the task of gauging ordinary meaning.”
Lee and Mouritsen now acknowledge the same about legal corpus linguistics methods: “[W]e concede that our corpus methods are also imperfect. Going forward, we envision a framework in which the search for ordinary meaning is informed by a sort of triangulation, in which corpus evidence, survey results, and purpose-based evidence are all brought to bear.” This appeal to “triangulation,” in which different sources of evidence are accorded evidential weight, is a hallmark of corpus moderatism. A good (i.e., well-conducted and well-analyzed) corpus linguistics study might provide some interpretive evidence, but it is not itself the measure of a legal text’s meaning. Nor does LCL obviously or necessarily outweigh contrary evidence about ordinary meaning from other interpretive sources, including dictionaries, intuition, historical evidence, legislative evidence, or surveys.
D. Legal Corpus Linguistics as “Evidence” of Meaning
The Corpus and the Critics offers an important reconceptualization of legal corpus linguistics. Lee and Mouritsen describe legal corpus linguistics results not as establishing, determining, or constituting ordinary meaning but as providing “evidence of ordinary meaning.” Actually, the new analysis is even more cautious—and rightly so. Lee and Mouritsen frequently describe their method as one that “may,” “might,” or “could” provide evidence. LCL won’t always be helpful. And even when it is, it does not provide us with ordinary meaning, but rather evidence of ordinary meaning.
Legal corpus linguistics offered as possibly relevant evidence is very different from legal corpus linguistics offered as the best measure of ordinary meaning, one that should generally trump other sources of interpretive evidence. As McCormick famously put it: “An item of evidence . . . need not prove conclusively the proposition for which it is offered. . . . A brick is not a wall.” This evidential view is a much more moderate vision of legal corpus linguistics—and a much more attractive one—which is shared by some of Lee and Mouritsen’s critics.1
It seems, then, that there is some agreement among Lee and Mouritsen and their critics (or, at least this critic). It is possible that good corpus linguistic analyses can—in some circumstances—provide relevant evidence about how an ordinary person would understand a legal text. And many other methods might also provide evidence about that fact.
E. Standards of “Good” Legal Corpus Linguistics
Lee and Mouritsen’s new gloss on corpus linguistics—as possibly relevant interpretive evidence—ratchets down many of their earlier claims. Legal corpus linguistics was once characterized as the “best mechanism” for finding ordinary meaning. Now it is characterized more humbly: it is just one possible source of evidence about ordinary meaning, which is to be weighed in “triangulation” with other sources.
With this new move, one key question is about the circumstances; In which legal-interpretive contexts, exactly, is Lee and Mouritsen’s legal corpus linguistics probative of ordinary meaning? Another key question is about the strength of good legal corpus linguistics evidence. In other words, when legal corpus linguistics is relevant, what is the probative value of good legal corpus linguistics? These central questions are not clearly answered in Lee and Mouritsen’s work. Their earlier writing suggests that legal corpus linguistics is generally more probative than competing sources of interpretive evidence. I read their new account, in The Corpus and the Critics, to back away from this suggestion. The appeal to “triangulation” acknowledges that legal corpus linguistics is not necessarily the sole or best evidence of ordinary meaning.
A third key question, addressed in this Essay, is: What constitutes “good” legal corpus linguistics evidence? This Part recommends eight minimum standards, which also seem to be endorsed by The Corpus and the Critics.
1. Analyze texts from the relevant time.
Not all legal corpus linguistics users are originalists. But for originalists, legal corpus linguistics offers an attractive tool to provide evidence about the Constitution’s “original public meaning.” That corpus linguistic inquiry should focus on texts published during the relevant time: constitutional debate and ratification. The U.S. Constitution was ratified by the states between 1787 and 1790, and the first ten Amendments between 1789 and 1791.
But there is one problematic detail about the Corpus of Historical American English (COHA): It contains historical texts from the 1810s to 2000s. As of January 2021, the Corpus of Historical American English contains no language data from the period of Constitutional debate and ratification. Its earliest data is from twenty years later. Moreover, the COHA does not include newspaper data until the 1860s, over seventy years after the Constitution’s ratification. The COHA contains data from four sources: fiction books, popular magazines, newspapers, and nonfiction books. Over half is from fiction.
The new Corpus of Founding Era American English (COFEA) is under construction to help solve this problem. It contains sources from 1760 to 1799. It is a smaller corpus than the COHA and contains very different sources. Today, nearly all of its documents (96%) come from Founders Online and consists of personal records, letters, and diaries from six men: Washington, Adams, Hamilton, Franklin, Jefferson, and Madison.2 By word count, those documents constitute 28% of the COFEA. This raises a second best practice of legal corpus linguistics: using representative and balanced corpora.
2. Use representative and balanced corpora.
All participants in the legal corpus linguistics debate agree that corpora should be sufficiently representative and balanced. These are fundamental principles of corpus linguistics. According to Douglas Biber, representativeness in a corpus is “the extent to which a sample includes the full range of variability in a population.” Stefan Gries helpfully elaborates:
By representative, I mean that the different parts of the linguistic variety I’m interested in are all manifested in the corpus. . . . By balanced, I mean that ideally not only should all parts of which a variety consists be sampled into the corpus but also that the proportion with which a particular part is represented in a corpus should reflect the proportion the part makes up in this variety and/or the importance of the part in this variety.
What representation and balance requires depends on the object of study. In the broader field of corpus linguistics (e.g., Biber and Gries above), representation and balance are well theorized. But the requirements of representation and balance are less clear in legal corpus linguistics debates. Legal corpus linguistics seeks evidence of “ordinary” or “public” meaning, a notion that is justified as a popular and democratic criterion of interpretation, related to reliance and notice values. Lee and Mouritsen’s recent article endorses that conception, which is focused on ordinary people’s language comprehension, not drafters’ language production.
Legal corpus linguistics, in the hands of textualists and originalists, aims to address an empirical question about how ordinary people understood language, not how elites produced it. If so, its proponents should say more about representativeness (and balance) of corpora with respect to the aim of identifying “ordinary meaning.” It is not immediately clear that the current corpus tools are representative with respect to this inquiry: the writings and correspondences of six elite men constitute a disproportionate share of the COFEA.
3. Don’t commit the Nonappearance or Uncommon Use Fallacies.
Some critics have cautioned legal corpus linguistics to avoid the “‘blue pitta problem,” or the “Nonappearance Fallacy.” These are claims that the nonappearance of some use in the corpus generally indicates that this use is incompatible with ordinary meaning. For example, a blue pitta is a bird of Asia, but is not mentioned as a “bird” in the COCA. Similarly, in some corpora, there are no examples of airplanes referred to as “vehicles.” But neither fact (in itself) indicates that the ordinary meaning of a legal text referring to “birds” excludes blue pittas or that the ordinary meaning of a legal text referring to “vehicles” excludes airplanes. The fact that a use is unattested in a corpus (e.g. no blue pitta “birds”) does not generally support the conclusion that the use falls outside of the “ordinary meaning” of a legal text containing that term.
A related fallacy is the “Uncommon Use Fallacy”: the relative rarity of some use in the corpus generally evinces that this use is outside of a law’s ordinary meaning. For example, suppose that we found just two references to a blue pitta as a “bird” or that only 2% of all “vehicle” references are to airplanes. Those facts (in themselves) would not provide evidence that “bird” excludes blue pittas or that “vehicle” excludes airplanes in a legal text.
Lee and Mouritsen are now clear: These fallacies “are straw men. We have not adopted and do not endorse the notion that any ‘use that is not reflected’ in a corpus (or is even only uncommonly reflected) cannot fall within the ‘ordinary meaning’ of a studied term.” This is a welcome clarification. Lee and Mouritsen elaborate that their recommended corpus analysis is not in any way limited to “expected applications.” The fact that a corpus does not include a reference to an X as a Y (or even the fact of very few references to an X as a Y) is not evidence that, in a legal text, Y excludes X. Lee and Mouritsen are adamant: “That has never been our claim, nor the point of corpus analysis.” (It is worth noting that this bad argument, which Lee and Mouritsen reject, is not even original expected applications, it is original attested applications. Even some expected applications may be unattested in the corpus.)
Part II of this Essay turns to courts’ use of legal corpus linguistics. But here is a small preview of a disconnect between LCL theory and practice. Justice Thomas’s citation of corpus linguistics in the Supreme Court is an often-celebrated example of legal corpus linguistics, cited again in the introduction to The Corpus and the Critics. In his dissent in Carpenter v. United States (2018), Justice Clarence Thomas cites legal corpus linguistics as evidence that “[a]t the founding, ‘search’ did not mean a violation of someone’s reasonable expectation of privacy. . . . The phrase ‘expectation(s) of privacy’ does not appear in . . . collections of early American English texts.”
Whatever one’s view of Fourth Amendment jurisprudence, Lee and Mouritsen’s new clarification makes clear that Justice Thomas’s use of legal corpus linguistics should be critiqued, not celebrated. This use of legal corpus linguistics is original attested applications, nonappearance-fallacy style reasoning. The mere fact that the phrase “expectation(s) of privacy” never appears in corpora (as a “search” or at all) does not provide evidence that the original meaning of the Fourth Amendment (including “unreasonable search”) necessarily excludes or is inconsistent with the concept of expectations of privacy.3
4. Don’t commit the Comparative Use Fallacy.
Another critique of legal corpus linguistics is the “Comparative Use Fallacy.” Some LCL proponents suggest that when considering two senses of a term, comparatively greater support for one sense in the corpus provides evidence that this sense is a better candidate for ordinary meaning. Lee and Mouritsen describe this as the “frequency fallacy,” the idea that the more commonly used sense of a term (as evinced by corpus linguistic analysis) is the better candidate for ordinary meaning.
Lee and Mouritsen are clear:
The “frequency fallacy” is another straw man. It has no foundation in our writing on law and corpus linguistics. Indeed, both of us have expressly disavowed an approach that merely seeks to determine the most common sense of a word and then labels that sense the ordinary meaning. As we have said, such an approach would be arbitrary.
Those familiar with Lee and Mouritsen’s writing may find this surprising. In Data-Driven Originalism, Lee and James C. Phillips write that comparing sense frequencies is the “meat-and-potatoes of determining meaning from corpus analysis.” They proceed to compare frequencies of competing senses and draw conclusions about public meaning. For example, they analyze the original meaning of “commerce” in the U.S. Constitution, reporting that “the trade-sense of commerce appears to be the dominant sense” (most frequent sense) in the corpus. What significance does that fact have? Lee and Phillips write:
[T]he corpus data on commerce give us a window into details that would never be visible upon consulting a founding-era dictionary or examining cherry-picked sentences from historical literature. Those materials could tell us that the various senses of commerce (trade, production, all economic activity, or all intercourse) are linguistically possible; but they could never give us empirical data on the relative frequency of these senses in the relevant time period. We can now consider hard data on that question—assembled in a systematic, transparent manner that is subject to falsification. And that data, at least arguably, tells us that the original meaning of commerce is the trade sense of the term.
Lee and Phillips propose that this analysis—a comparison of raw sense frequencies—is their corpus linguistics method that provides the most insight into the “communicative content” of the Constitution. They conclude that “[a] judge who takes original meaning seriously . . . would have a very difficult time justifying a production sense of commerce in light of our data. . . . [The economic activity sense cannot be rejected, but] the data would provide a basis for choosing the trade sense of commerce over the others.” To be sure, there is sometimes hedging: the data tells us the original meaning, “at least arguably.” But there is not always hedging: In the conclusion Lee and Phillips clarify that and the data “would provide a basis” for “choosing” the trade sense of commerce over the others as the ordinary meaning (emphasis added).
In Judging Ordinary Meaning, Lee and Mouritsen’s corpus analyses are also centered around exactly this kind of frequency-based sense comparison, sometimes with respect to a certain context but sometimes not. Lee and Mouritsen’s analysis of Muscarello v. United States (1998) did so: “The Muscarello question—of the meaning of carry—is likewise susceptible to measurement. We can assess the relative frequency of the personally bear sense and the transport sense using corpus analysis.” Their analysis of Taniguchi v. Kan Pacific Saipan, Ltd. (2012) did so as well: “We can also measure the relative frequency of the written translator and oral translator senses of interpreter.” Likewise, they used frequency-based sense comparison in analyzing United States v. Costello (7th Cir. 2012):
[T]he question turns on the meaning of a transitive verb and its relation to its object . . . . We would therefore look to the corpus data to tell us which senses of harbor are the most frequent, common, or possible senses of harbor, and to help us make informed decisions about sense division.
Do Lee and Mouritsen no longer believe that this data informs questions of ordinary meaning? Would they, for example, now reject the inference quoted above about legal corpus linguistics and the Commerce Clause? Maybe. In The Corpus and the Critics, they now write that the significance of frequency data is not a question for them, but one “for legal theory”:
The last step is to determine the significance of the corpus evidence. Here we return to the “closely related senses” problem. This is a key, unresolved problem in law and corpus linguistics. . . . In Judging Ordinary Meaning, we offered a starting point for a response to this problem. We suggested that even where two senses of a statutory term are closely related, the fact that one of them is overrepresented in a corpus may tell us something important—that that sense is “likely to be the one that first comes to mind when we think of this term.” We conceded that this “top-of-mind sense . . . may not exhaust the breadth of human perception of th[e] term,” since on reflection, “some people might concede that the term encompasses” other, less common examples. And we noted that the choice between the two senses (“top-of-mind” versus broader, “reflective” sense) “is not a deficiency in corpus data” but a problem for our legal theory of interpretation. The choice will be “dictated in part by the rationales that drive us to consider ordinary meaning”—“[a] concern for fair notice and protection of reliance interests may [ ] direct us to stop at the top-of-mind sense of a statutory term,” while other rationales could press us to endorse a broader, reflective sense.
So the “meat-and-potatoes” frequency data is not necessarily evidence of ordinary meaning. On the new account it seems that whether it is evidence is no longer an empirical question with an objective answer, but rather one that depends on one’s personal “legal theory.”
There is still one “objective” fact that Lee and Mouritsen claim this analysis delivers: The fact that one sense appears more often in a corpus may tell us that the sense is “likely to be the one that first comes to mind.” However, studies in corpus linguistics and psycholinguistics don’t support such a straightforward link between frequency and ease of accessibility in a speaker’s mind. A recent paper by Brian Slocum and Stefan Gries emphasizes that frequency data can be particularly misleading when not accounting for dispersion, how a word is distributed over a corpus.
But even when a frequently occurring sense is dispersed smoothly across a corpus, this “top-of-mind” assumption may not hold. Lee and Mouritsen suggest that a sense that appears most frequently in a corpus is likely to be the “top-of-mind sense,” which they claim is more related to fair notice and reliance interests. But this is not true: When a term has multiple senses, frequency of one sense of a term in a corpus does not always tell us how people would disambiguate the sense in a legal text containing that term.
Take a simple example. Suppose a legal text contains a rule using masculine pronouns (e.g., “he”). Consider the U.S. Constitution Article I, Section 2: “No Person shall be a Representative who shall not have attained the Age of twenty five Years . . . and who shall not, when elected, be an Inhabitant of that State in which he shall be chosen” (emphasis added). Is the ordinary meaning a rule that applies only to men, or to persons of all genders? How should we interpret “he” in legal rules? There are different senses of “he.” Merriam-Webster contains several definitions of “he.” One is a gender-neutral sense: “used in a generic sense or when the gender of the person is unspecified // he that hath ears to hear, let him hear.” Another is a gendered sense: “a male person or animal.”
Suppose that the legal text does not provide any other indication of the relevant sense of “he.” So we conduct a Lee and Mouritsen–style corpus linguistics search, searching “he” in the corpus. Or perhaps we search in some subset of the corpus, to accommodate the statute’s “context.” For example, we might search for “he” occurring near “Representative,” to take account of the “context” of Article I, Section 2. Across hundreds of uses, we record how often “he” refers to men and how often “he” is used in a gender-neutral way. Inevitably, we’ll arrive at a very precise number: say, in 90.4% of all uses, “he” refers to a man.
So the gendered sense of “he” is much more frequently occurring. But should we conclude, in light of that fact, that an ordinary person would understand the legal text to only apply to men? I don’t think so. In fact, in empirical work with Brian Slocum and Victoria Nourse, we confirm that ordinary people typically take “he” to refer gender-inclusively in legal rules. Data about 90% of all recorded uses may seem compelling, but usage patterns in works of fiction and newspapers do not always reflect ordinary people’s understanding of legal rules. The LCL focus on “most common use” (even the most common use, in the relevant “context”) can lose sight of what’s at stake in interpretation. Lee and Mouritsen are right to focus on “fair notice” and “reliance interests.” But works of fiction and newspapers don’t have fair notice and reliance interests; people do.
5. Take account of the “context” of the language.
Lee and Mouritsen also endorse taking account of linguistic “context”:
In Judging Ordinary Meaning, we presented the linguistic basis for the need to assess the ordinary meaning of words or phrases in light of all their relevant context. We noted that words are not understood in isolation but in context. And we highlighted the salience of both syntactic context (surrounding words and language structures) and pragmatic context (the physical or social setting in which the words appear).
These comments come in Lee and Mourtisen’s critique of using surveys as evidence of ordinary meaning. For example, Testing Ordinary Meaning surveyed ordinary people with very simple questions like “whether an airplane is a vehicle.” Lee and Mouritsen claim that this type of question is flawed because it ignores the relevant context of “vehicle” as it would be used in a legal text.
This critique is surprising, given Lee and Mouritsen’s program. Their paradigmatic LCL analysis involves extracting a term from a legal text (“vehicle”, “harbor”, “commerce,” etc.) and analyzing its use within a subset of a corpus (which they describe as the appropriate “context”). For that analysis to have any relevance to the ordinary meaning of a legal text requires exactly the assumption they now reject.
For example, imagine that we are conducting a legal corpus linguistics analysis to answer the interpretive question in McBoyle v. United States (1931): Is an airplane a vehicle? Well, the question is actually more complex when we consider the full context of the statute at issue in McBoyle:
Sec. 2. That when used in this Act: (a) The term ‘motor vehicle’ shall include an automobile, automobile truck, automobile wagon, motor cycle, or any other self-propelled vehicle not designed for running on rails . . . .
Sec. 3. That whoever shall transport or cause to be transported in interstate or foreign commerce a motor vehicle, knowing the same to have been stolen, shall be punished by a fine of not more than $5,000, or by imprisonment of not more than five years, or both.
Did someone who knowingly transported a stolen airplane across state lines violate this statute? In Judging Ordinary Meaning, Lee and Mouritsen address McBoyle, making an identical assumption to the one they now critique. They examined the collocates of “vehicle” across certain time slices of the NOW and COHA. This corpus evidence about that simple term “vehicle” was offered as probative, telling us something about the ordinary meaning of “vehicle” in the McBoyle statute. There is no additional consideration of context. The same is true for other analyses, such as the LCL analysis of “commerce” discussed previously.
Of course, I agree with Lee and Mouritsen. The best textualist analysis should not focus myopically on the word “vehicle,” but should consider the meaning expressed by the full statutory text—all eighty-six words above. But treating the statute as the unit of analysis is impossible with Lee and Mouritsen’s legal corpus linguistics. That string of eighty-six words would never appear in an LCL search. So what Lee and Mouritsen really mean by studying the “ordinary meaning” of a statute with LCL is studying something about individual terms and inferring from that analysis a broader conclusion about the meaning of a legal text containing those terms.
Now, sometimes Lee and Mouritsen suggest a way to accommodate “context” when searching the corpus. But what they mean by “context” is really an approximation of the much richer statutory context. In practice, this means something like searching for “vehicle” in the corpus, only when it appears close to the word “transport.” That is a far cry from studying “words or phrases in light of all their relevant context.” The method still extracts a term from its rich statutory context and assesses its use in some subset of the corpus (e.g., where “vehicle” appears near “transport”). We can call that subset of the corpus “a context” (e.g., the “transport-a-vehicle” context), but to assume that that “context” is comparable to the statutory one is very controversial. One might think that the subset is better described a hodgepodge of uses of “vehicle” near “transport,” across many contexts—differing from each other and from the statutory context. And Lee and Mouritsen must again assume that those additional contextual features don’t render the analysis useless. It is these worries that encourage critics’ calls for much more attention to context, with qualitative—not just quantitative—linguistic analysis.
Lee and Mouritsen’s simplifying assumptions about context are controversial. Remember Stanley Fish’s critique: “Once you detach patterns from the intentional context in which they have significance, you can’t get the significance back.” Studying uses of “vehicle”, or even uses of “vehicle” near “transport” can tell us interesting things about patterns of language use. But can it really tell us something about the meaning of “vehicle” within the context of the McBoyle statute?
Rejecting those simplifying assumptions is not a problem for survey proponents: It is possible to provide survey participants with the full text of a statute. But it is a problem for LCL proponents, as these assumptions are the foundation of the legal corpus linguistics program. LCL proponents have more work to do in justifying these assumptions, but it is commendable that Lee and Mouritsen note the importance of “context” and the dangers in ignoring additional contextual features.
6. Acknowledge that corpus data might ultimately be unhelpful.
Lee and Mouritsen are clear that there are least some circumstances in which legal corpus linguistics might ultimately be “unhelpful.” This is a simple, but important principle of legal corpus linguistics. Although thoughtful analyses could sometimes provide evidence of ordinary meaning, in other circumstances they might not.
7. Acknowledge the possibilities of linguistic indeterminacy.
There is one final principle that Lee and Mouritsen helpfully highlight. Legal corpus linguistics may provide evidence of linguistic indeterminacy:
[T]he insights from the corpus linguistics project can offer ammunition to those who seek to question the objectivity or determinacy of the search for ordinary (or original) meaning. To that extent this tool may be quite valuable to the antitextualist, or living constitutionalist—who may use corpus linguistic methods to highlight the indeterminacy of language.
This is importantly different from Part I.E.6, the acknowledgment that LCL could be “unhelpful.” Sometimes, legal corpus linguistics might not be well-suited to providing relevant evidence about the question; but in other circumstances, LCL could uncover evidence of indeterminacy. Of course, that possibility is not just for the antitextualist. The objective textualist should also be open to possibility of linguistic indeterminacy.
8. Do not rely on “intuition” that may be biased.
In earlier work, Lee and Mouritsen were very skeptical of judicial intuition. The Corpus and the Critics, is more open-minded about “judicial intuition”:
We are quite in favor of the use of this tool. We just think that intuition about linguistic facts, unchecked by evidence, runs the risks (if not the guarantee) of confirmation bias and motivated reasoning. And again, these are the very risks that a proponent of fair notice ought to be interested in avoiding.
It is somewhat strange that this skepticism about intuition does not extend to the use of intuition in LCL analysis. For instance, Lee and Mouritsen rely entirely on intuition in assessing the frequencies returned by their corpus linguistic analyses (i.e. evaluating whether one sense is “more common” than another). A possible remedy is to employ more sophisticated statistics. As Stefan Gries puts it:
[S]ince corpus data only provide distributional information in the sense mentioned earlier, this also means that corpus data must be evaluated with tools that have been designed to deal with distributional information[;] and the discipline that provides such tools is statistics. And this is actually completely natural: psychologists and psycholinguists undergo comprehensive training in experimental methods and the statistical tools relevant to these methods[,] so it’s only fair that corpus linguists do the same in their domain. After all, it would be kind of a double standard to on the one hand bash many theoretical linguists for their presumably faulty introspective judgment data, but on the other hand then only introspectively eyeball distributions and frequencies.
More foundationally, Lee and Mouritsen rely on intuition to categorize the concordance lines returned by their corpus searches (i.e. intuitively categorizing usage data returned by searches as examples of “sense-1” or “sense-2”). If LCL is concerned about confirmation bias and motivated reasoning affecting intuition, those same concerns would apply to a judge, clerk, or scholar intuitively categorizing concordance lines.
This is not an impossible problem to solve. For example, James Phillips and Jesse Egbert recommend employing multiple “blind” coders, to assess corpus linguistics data independently. In some past academic work, Lee has employed coders in this task. Even better would be “blind” coders, entirely unfamiliar with the legal dispute, who are less likely to be politically or outcome-motivated in their categorizations. Lee and Mouritsen are rightly concerned about intuition, and addressing this concern in the context of LCL warrants using more sophisticated statistics (rather than eyeballing frequencies) and employing multiple “blind” coders, unfamiliar with the debate, to evaluate concordance lines.
II. The Courts
This Part turns from the academic debate to practice. A number of courts have taken up legal corpus linguistics methods. Part II.A collects and analyzes these cases. There are three quantitative findings: (a) the use of legal corpus linguistics has increased dramatically since 2011, and particularly in the past three years, (b) judges are largely conducting legal corpus linguistic analyses themselves (i.e. not relying on experts), and (c) legal corpus linguistics tends to be treated favorably by Republican-appointed judges and negatively by Democratic-appointed judges.
Part II.B turns to a qualitative analysis of these cases. Some of the favorable uses of legal corpus linguistics run afoul of the best practices endorsed by Lee and Mouritsen. The commendable care endorsed in recent academic work is not always reflected in the practice of legal corpus linguistics. For LCL to fulfill its promise as an objective, neutral, and apolitical method of interpretation, courts should meet at least these minimum standards.
A. Judicial Opinions Citing Legal Corpus Linguistics
This Part aims to collect the universe of cases using legal corpus linguistics in legal interpretation. Cases were collected in December 2020 by searching Westlaw for citations to (a) “corpus linguistics,” (b) the article “Judging Ordinary Meaning,” (c) the “Corpus of Historical American English,” (d) the “Corpus of Contemporary American English,” and/or “www.english-corpora.org.” The resulting list of cases was cross-checked with Clark Cunningham’s list of resources on law and linguistics; all nine cases on the Cunningham list were returned via the Westlaw searches. One very recent case was added by recommendation on February 28, 2021.4
Table 1 below lists the cases using legal corpus linguistics. Nine cases that were returned on Westlaw are not presented in the table below. Seven cite an academic article with “corpus linguistics” in its title but do not consider corpus linguistics evidence. Those are: State v. Thonesavanh (Minn. 2017)5 ; Exotic Motors v. Zurich American Ins. Co., (Mo. Ct. App. 2020)6 ; Neese v. Utah Board of Pardons and Parole, 7 (citing Triangulating Public Meaning8 ; Napilitano v. St. Joseph Catholic Church and Thomas Walden (Fla. Dist. Ct. App. 2020)9 ; Brady v. Park (Utah 2019)445 P.3d 395 (Utah 2019).10 ; Jones v. Governor of Florida (11th Cir. 2020)11 (citing Original Meaning and the Establishment Clause: A Corpus Linguistics Analysis12 . Two others, Deckers Outdoor Corp. v. Australian Leather Pty. Ltd. (N.D. Ill. 2018)13 and Leadership Studies Inc. v. Blanchard Training and Development Inc. (S.D. Cal. 2018),14 cite corpus linguistic analyses presented as evidence of consumer expectations (not ordinary meaning) in trademark disputes.
The thirty cases appear in Table 1. The first column lists the citation; the next column indicates whether the opinion cites Judging Ordinary Meaning (“JOM”), the Corpus of Historical American English (“COHA”), the Corpus of Contemporary American English (“COCA”), and/or the Corpus of Founding Era American English (“COFEA”).
The next two columns record whether corpus linguistics is discussed favorably or critically. Inevitably, those categorizations require some judgment, but displaying the cases transparently in the table allows others to evaluate those categorizations. When legal corpus linguistics is discussed favorably or critically, the judge’s name (and concurrence or dissent) is noted. The table also includes the political party of the appointing President or Governor; appointing Presidents are named. In a few cases, the discussion was not clearly favorable or critical—that is mentioned in “Notes,” which also presents some key quotations from the cases.
[ninja_tables id=”2227″]
There are three main findings from this brief survey. First, the use of legal corpus linguistics has increased dramatically since 2011, and particularly in the last three years. See Figure 1. The six opinions discussing legal corpus linguistics between 2011 and 2017 come from Utah and Michigan state courts. The picture is very different in the past three years. But between 2018 and 2020, legal corpus linguistics was cited in the U.S. Supreme Court; in the D.C., Federal, Third, and Sixth Circuits; in U.S. District Courts; and in state courts in Alabama, Idaho, Michigan, Montana, Ohio, and Utah.
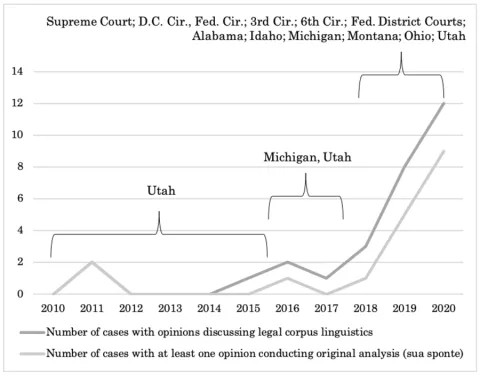
Figure 1: Opinions Discussing and Conducting (sua sponte) Legal Corpus Linguistics, 2010–2020
Second, judges are conducting legal corpus linguistic analyses themselves, not only relying on experts or briefs. Judges are frequently conducting sua sponte legal corpus linguistic analyses, annotated with a “*” after the citation in Table 1. Professional linguists have cautioned against this practice, recommending that judges consult expert linguists, rather than conduct analyses themselves. Consider Slocum and Gries:
Lee and Mouritsen tell us why only “a little background and training” is sufficient for judges. It is because “judges and lawyers are linguists.” Justice’s [sic] Lee’s assessment that “[corpus linguistics] isn’t rocket science” sounds pithy, but . . . at this point in time, it is highly doubtful the cost/benefit analysis of judges and lawyers acquiring the knowledge necessary to perform corpus linguistics competently points in favor of widespread judicial adoption. Nevertheless, publicizing the kind of knowledge that can be gained from linguistic work may encourage judges to avail themselves of the services of linguists or, more likely, gain a greater understanding of the nature and functioning of language.
Finally, favorable uses of legal corpus linguistics tend to come from Republican appointees, while critiques come from Democratic appointees. Of the favorable citations, twenty-three came from Republican appointees, two from Democratic appointees, and two from elected judges with no declared party. Of the critical citations, six came from Democratic appointees and one from Republican appointees.
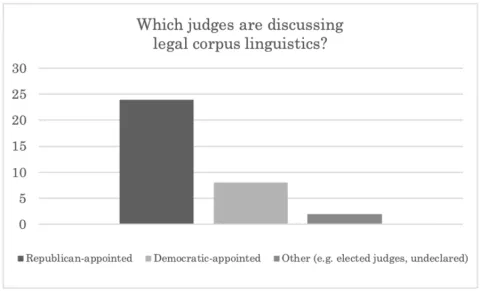
Figure 2: Discussions of Legal Corpus Linguistics, by Party of Appointing President or Governor (per curiam decision omitted)
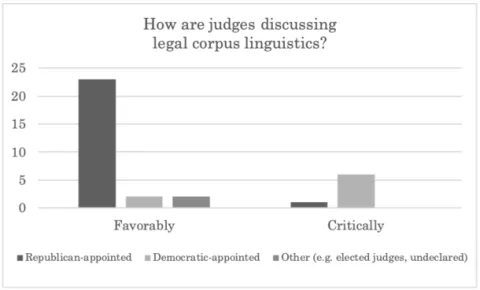
Figure 3: Favorable and Critical Discussions of Legal Corpus Linguistics, by Party of Appointing President or Governor (per curiam decision omitted)
B. Analyzing Judicial Uses of Corpus Linguistics
This part turns to a qualitative analysis of judicial uses of legal corpus linguistics, comparing the practiced to the best practices outlined in Part I.
1. Analyze texts from the relevant time.
Overall, the courts are doing well in considering texts from the relevant time period. For example, no cases apply the COHA (with texts no earlier than 1810) to constitutional interpretation.
At the same time, very few courts included details suggesting careful scrutiny of individual concordance lines. This can be important. For example, in State v. Lantis, the court set out to conduct an LCL analysis of the phrases “disturb the peace,” “disturbing the peace,” and “disturbed the peace,” from “1850 to 1890.” The COHA returned sixty-nine responses (which really reflect language use between 1850 and 1910).
It is possible to inspect those sixty-nine responses by reproducing the search. One of the items included is a letter from Corcuera to Felipe IV (concerning an archbishop who took away a female slave from an artilleryman, which Corcuera describes as an act which did not fail to “annoy me and disturb the peace”). That fragment of text made it into the 1850-to-1910 search because it was reprinted in 1903. But that language was originally from 1636 letter.
Courts should exercise caution and ensure that each result actually reflects language use from the relevant time. Without scrutinizing each line, courts cannot rule out that some language-use examples reflect usage from other decades, or even centuries.
2. Use representative and balanced corpora.
There are a few explicit mentions of representativeness and/or balance: in Nycal, Rasabout, and Wilson. In all other cases, these concepts are not discussed. Judges may not be sufficiently apprised of the significance of representativeness and balance. As discussed previously (Part I.E.2), this is also a pressing area for legal corpus linguistics theorists: What does “representativeness” mean in the context of researching “ordinary meaning,” (an empirical fact about language consumption by ordinary people, not language production from elites), and which corpora are representative in that sense?
3. Don’t commit the Nonappearance or Uncommon Use Fallacies.
As discussed in Part I.E.3, Justice Thomas’s Carpenter analysis employs a classic nonappearance style argument about the phrase “expectations of privacy.” There are also nonappearance and uncommon-use arguments in several other cases: State v. Burke,“[A] simple search for the word ‘incarceration’ in the . . . COHA, reveals 442 uses of incarceration in the 400-million-word database between 1810 and 2009. None of these uses involved ‘incarceration’ in a mental institution, and only three referenced incarceration in an asylum. These results once again evidence the usefulness and objectivity of determining the meaning of words through corpus linguistics, rather than through simply turning to a dictionary to reach a desired result.” State in Interest of J.M.S.,“In contemporary usage, ‘abortion procedure’ references the termination of a pregnancy under medical conditions, such as in a clinic and under the supervision of a physician. This conclusion is based on a review of every instance in which the words ‘abortion’ and ‘procedure’ co-occur in the Corpus of Contemporary American Usage. . . . Not once were the terms used to connote an ad hoc, violent, nonmedical effort to terminate a fetus (as by striking the mother’s abdomen).” and United States v. Woodson (“[T]he Corpus of Contemporary American English, which provides insight into how the word ‘scheme’ is used in ordinary speech, offers no examples of the word ‘scheme’ being used to refer to a tangible thing similar to a criminal hideout.”).
4. Don’t commit the Comparative Use Fallacy.
Comparative use arguments are extremely common in the sample: Bright, Buckhanon, Caesar’s Entertainment Corp., Drouillard, In re Adoption of Baby E.Z., Murray, Nycal, Richards, State v. Burke, and State v. Rasabout.
As just one example, take Drouillard, which concerned the applicability of an insurance policy requiring that “[t]he vehicle must hit, or cause an object to hit,” an insured, a covered auto, or a vehicle an insured is occupying. The parties agree to the key facts: that “the drywall left the bed of the truck; that the drywall came to rest in the road; and that, shortly thereafter, the ambulance collided with the drywall as the drywall lay stationary in the road.”
The dissent makes a standard comparative-use argument:
“The issue here is remarkably straightforward: whether certain drywall lying stationary on a road can properly be said to have ‘hit’ a moving insured motor vehicle, thereby entitling plaintiff to uninsured motorist coverage . . . Of the 1,895 relevant excerpts in COCA in which the word ‘hit’ (employed as a verb) is collocated within four words of objects that are generally stationary (a wall, a fence, a guardrail, a nail, a curb, a post, a mailbox, a floor, the ground), there are only thirteen excerpts at the most—approximately 0.68% of all relevant excerpts—that could even arguably be interpreted as communicating that a stationary object can “hit” something else. The remaining 1,882 excerpts—approximately 99.3% of all relevant excerpts—describe the stationary object as being “hit” by something else, not as doing the ‘hitting.’ These data reinforce what I believe is already a commonly understood proposition: in common American-English parlance, the moving object ‘hits’ the stationary object; the stationary object does not ‘hit’ the moving object.”
5. Take account of the context of the legal language.
The previous example also makes clear the significance of context, exemplifying the strength of LCL’s simplifying assumptions. Consider the actual language of the policy: “The vehicle must hit, or cause an object to hit” a covered vehicle. One might worry that the LCL analysis of the dissent, by stripping “hit” from its context, has dramatically changed the question. The LCL analysis concerns the use of “hit.” The dissent searches the corpus with this new question, reports a big number (99.3%), and treats this as evidence of the ordinary meaning of the insurance policy. But does this tell us whether people would take the policy’s language to apply? Only if we assume that people’s understanding of “the drywall “hit the ambulance” is equivalent to their understanding of the truck “caused the drywall to hit the ambulance.”
Many cases adopt an analysis similar to that in Drouillard—extracting one term from a legal text and searching for it in the corpus, with little attention to the role of context. Lee and Mouritsen admirably emphasize, in their recent work, the importance of context, but those recommendations have not been seriously implemented in some judicial uses of LCL.
6. Acknowledge that corpus data might ultimately be unhelpful.
There are a few cases that admirably acknowledge that corpus data might ultimately be unhelpful. For example, Justice Lee notes in Bright v. Sorensenthat “[i]n this instance, however, our corpus analysis was inconclusive. . . . The data, while inconclusive, are nonetheless useful.” Judge Thapar similarly writes in Wright v. Spaulding that “corpus linguistics turned out not to be the most helpful tool in the toolkit.”
7. Acknowledge the possibilities of linguistic indeterminacy.
None of the thirty cases took corpus linguistics data as evidence of linguistic indeterminacy. There are, of course, multiple possible explanations for that finding. Perhaps none of the cases in this sample involved linguistic indeterminacy.
8. Do not rely on “intuition” that may be biased.
None of the thirty cases employed multiple (or even single) independent or blind coders to objectively assess the data returned by the legal corpus linguistics search.
Conclusion
It is often said that “it takes a theory to beat a theory.” The Corpus and the Critics gestures towards this conventional wisdom in defense of corpus methods: “None of our critics offer a framework. . . . [W]ithout a replacement method for resolving these kinds of cases, the utility of such criticism is limited.”
But Lee and Mouritsen have not offered a theory. They are emphatic: “Corpus linguistic analysis is not a theory of interpretation; it is a tool.” Some of the most difficult questions are now flagged as ones “for legal theory,” to be answered elsewhere: “[M]any of the problems we encounter in the law and corpus linguistics movement are rooted in imprecisions in legal theory, not in problems with corpus linguistics.”
Lee and Mouritsen also propose that “[i]t takes a method to beat a method.” They offer this reply to some of their critics: “Zoldan and Bernstein offer no alternative mechanism for assessing the communicative content of the language of law.” It is not obvious what Lee and Mouritsen mean by “method.” Often they characterize LCL as merely an interpretive “tool.” On that thin meaning of a “method” (the identification of sources of possibly relevant legal-interpretive evidence), both they and their critics have methods.
A richer sense of “method” involves not only identifying sources of possibly relevant interpretive evidence, but elaborating more precisely how to interpret legal texts, including how to use interpretive tools. Lee and Mouritsen gesture in that direction: “[W]e concede that our corpus methods are also imperfect. Going forward, we envision a framework in which the search for ordinary meaning is informed by a sort of triangulation, in which corpus evidence, survey results, and purpose-based evidence are all brought to bear.”
Lee and Mouritsen often focus on the promise of LCL as a “tool,” conducting LCL analyses as proofs of concept, emphasizing what LCL might possibly achieve, and noting how judges might possibly use it—but not how judges should use it. Many have been excited to learn what a legal interpreter could possibly do with legal corpus linguistics. But as the LCL movement matures, it is time to address the harder questions. These tools may have “promise,” but fulfilling that promise requires detail on method: How exactly should legal interpreters use these tools? (And that question should not be sidelined as “one for legal theory.”)
The Corpus and the Critics is admirable for taking a step in this direction. By disaffiliating their methodology from certain criticisms, Lee and Mouritsen have in effect begun to outline a legal corpus linguistics method. This Essay has worked to crystallize and elaborate some of those commitments. It proposed eight recommendations that should serve as minimum standards for legal corpus linguistics. Those in the legal corpus linguistics movement should also develop additional guidelines, with an eye to extant sophisticated work in (non-legal) corpus linguistics, and an ear to expert linguists. As judges increasingly conduct sua sponte legal corpus linguistic analyses, it is crucial for proponents to not only suggest what LCL might possibly tell us but to also clarify how one should use these new tools—elaborating how to do legal corpus linguistics well.
More skeptical critics might worry that this Essay concedes too much. I sympathize with those concerns; this is not the first time that a new scientific tool promises to “create a system of legal thought that is objective, neutral, and apolitical.” Legal corpus linguistics promises neutral and objective interpretive evidence, with empirical methods. It is possible to assess the merits of this claim, by looking at both theory and practice: Do its proponents disavow legal corpus linguistics arguments that do not actually meet their standards (e.g. “original attested applications” and nonappearance fallacy arguments); do they openly commit to specific best practices; do they critique mistaken and incautious judicial uses of the tool; do they welcome that legal corpus linguistics can evince linguistic indeterminacy—for textualists and nontextualists alike; and are interpreters who are favorable to LCL similarly moved whether it supports liberal or conservative conclusions? Each “no” is more fuel for the skeptic’s fire, each “yes” a boon to LCL’s success.
The legal corpus linguistics movement is off the ground. For that its founders are owed enormous congratulations. LCL offers an exciting new tool for legal interpretation. But those committed to its neutrality, objectivity, and empirical rigor should attend to its methodology, in theory and in practice. Will corpus proponents remain enthusiasts, celebrating any judicial use of legal corpus linguistics, unresponsive to those who employ these tools incautiously or incorrectly? Or might they themselves become critics, neutral commentators on the uses and misuses of their tools, proponents not of “more legal corpus linguistics” but of “good legal corpus linguistics”? Time will tell.
- 1Of course, judicial inquiries into ordinary meaning are not governed by rules of evidence. Nevertheless, given LCL’s claims to provide “evidence” through a scientific method, it is worth reflecting on the analogy. For example, Part II describes courts’ sua sponte legal corpus linguistic analyses. Would those methods of LCL meet traditional standards of evidence: Has the method been tested; has it been subjected to peer review and publication; what is its known and potential error rate; what standards control its operation; and has it gained widespread acceptance within the scientific community (of professional linguists)?
- 2Note that Founders Online also includes the writings of John Jay, but these are not included in the COFEA.
- 3To the contrary, historical work by Orin Kerr suggests that the “reasonable expectation of privacy” test is actually consistent with the original meaning of the Fourth Amendment. Orin S. Kerr, Katz as Originalism (unpublished manuscript).
- 4Thanks to Stephen Mouritsen for calling my attention to this recent case.
- 5904 N.W.2d 432 (Minn. 2017).
- 6597 S.W.3d 767 (Mo. Ct. App. 2020). (citing Judging Ordinary Meaning for a proposition to support a dictionary use)
- 7(Utah 2017)416 P.3d 663 (Utah 2017).
- 8Lawrence B. Solum, Triangulating Public Meaning: Corpus Linguistics, Immersion, and the Constitutional Record, 2017 BYU L. Rev. 1621 (2018).)
- 9Case No. 5D19-3112 (Fla. Dist. Ct. App. Dec. 18, 2020).
- 10 (calling for courts to gain greater knowledge of linguistics)
- 11975 F.3d 1016 (11th Cir. 2020).
- 12Stephanie H. Barclay, Brady Earley & Annika Boone, Original Meaning and the Establishment Clause: A Corpus Linguistics Analysis, 61 Ariz. L. Rev. 505, 528–29 (2019).)
- 13340 F. Supp. 3d 706 (N.D. Ill. 2018).
- 142018 WL 1989554 (S.D. Cal 2018).